
如何选择优化器 optimizer_2
转自:https://www.jianshu.com/p/d99b83f4c1a6
在很多机器学习和深度学习的应用中,我们发现用的最多的优化器是 Adam,为什么呢?
下面是 TensorFlow 中的优化器,
https://www.tensorflow.org/api_guides/python/train
在 keras 中也有 SGD,RMSprop,Adagrad,Adadelta,Adam 等:
https://keras.io/optimizers/
我们可以发现除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢?
在 Sebastian Ruder 的这篇论文中给出了常用优化器的比较,今天来学习一下:
https://arxiv.org/pdf/1609.04747.pdf
本文将梳理:
每个算法的梯度更新规则和缺点
为了应对这个不足而提出的下一个算法
超参数的一般设定值
几种算法的效果比较
选择哪种算法
一. 优化器算法简述?
首先来看一下梯度下降最常见的三种变形 BGD,SGD,MBGD,
这三种形式的区别就是取决于我们用多少数据来计算目标函数的梯度,
这样的话自然就涉及到一个 trade-off,即参数更新的准确率和运行时间。
- Batch gradient descent
梯度更新规则:
BGD 采用整个训练集的数据来计算 cost function 对参数的梯度:
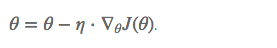
缺点:
由于这种方法是在一次更新中,就对整个数据集计算梯度,所以计算起来非常慢,遇到很大量的数据集也会非常棘手,而且不能投入新数据实时更新模型
我们会事先定义一个迭代次数 epoch,首先计算梯度向量 params_grad,然后沿着梯度的方向更新参数 params,learning rate 决定了我们每一步迈多大。
Batch gradient descent 对于凸函数可以收敛到全局极小值,对于非凸函数可以收敛到局部极小值。
- Stochastic gradient descent
梯度更新规则:
和 BGD 的一次用所有数据计算梯度相比,SGD 每次更新时对每个样本进行梯度更新,
对于很大的数据集来说,可能会有相似的样本,这样 BGD 在计算梯度时会出现冗余,
而 SGD 一次只进行一次更新,就没有冗余,而且比较快,并且可以新增样本。
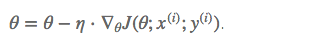
看代码,可以看到区别,就是整体数据集是个循环,其中对每个样本进行一次参数更新。
缺点:
但是 SGD 因为更新比较频繁,会造成 cost function 有严重的震荡。

BGD 可以收敛到局部极小值,当然 SGD 的震荡可能会跳到更好的局部极小值处。
当我们稍微减小 learning rate,SGD 和 BGD 的收敛性是一样的。
- Mini-batch gradient descent
梯度更新规则:
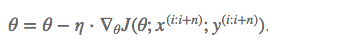
MBGD 每一次利用一小批样本,即 n 个样本进行计算,
这样它可以降低参数更新时的方差,收敛更稳定,
另一方面可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。
和 SGD 的区别是每一次循环不是作用于每个样本,而是具有 n 个样本的批次
超参数设定值:
n 一般取值在 50~256
缺点:
不过 Mini-batch gradient descent 不能保证很好的收敛性,
learning rate 如果选择的太小,收敛速度会很慢,如果太大,loss function 就会在极小值处不停地震荡甚至偏离。
有一种措施是先设定大一点的学习率,当两次迭代之间的变化低于某个阈值后,就减小 learning rate,不过这个阈值的设定需要提前写好,这样的话就不能够适应数据集的特点。
此外,这种方法是对所有参数更新时应用同样的 learning rate,如果我们的数据是稀疏的,我们更希望对出现频率低的特征进行大一点的更新。
另外,对于非凸函数,还要避免陷于局部极小值处,或者鞍点处,因为鞍点周围的error 是一样的,所有维度的梯度都接近于0,SGD 很容易被困在这里。
鞍点就是:一个光滑函数的鞍点邻域的曲线,曲面,或超曲面,都位于这点的切线的不同边。
例如这个二维图形,像个马鞍:在x-轴方向往上曲,在y-轴方向往下曲,鞍点就是(0,0)
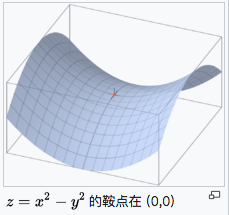
为了应对上面的三点挑战就有了下面这些算法。
[应对挑战 1]
- Momentum
SGD 在 ravines 的情况下容易被困住, ravines 就是曲面的一个方向比另一个方向更陡,这时 SGD 会发生震荡而迟迟不能接近极小值:
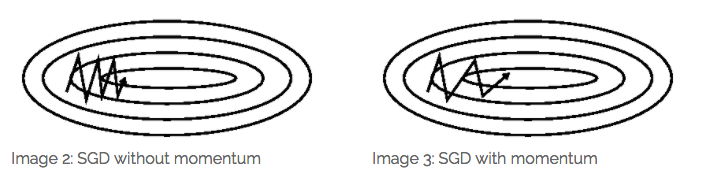
梯度更新规则:
Momentum 通过加入 γv_t?1 ,可以加速 SGD, 并且抑制震荡
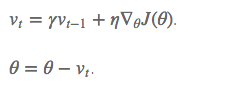
当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。
加入的这一项,可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
超参数设定值:
一般 γ 取值 0.9 左右。
缺点:
这种情况相当于小球从山上滚下来时是在盲目地沿着坡滚,如果它能具备一些先知,例如快要上坡时,就知道需要减速了的话,适应性会更好。
- Nesterov accelerated gradient
梯度更新规则:
用 θ?γv_t?1 来近似当做参数下一步会变成的值,则在计算梯度时,不是在当前位置,而是未来的位置上
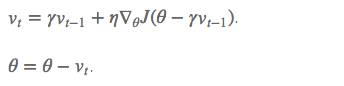
超参数设定值:
γ 仍然取值 0.9 左右。
效果比较:
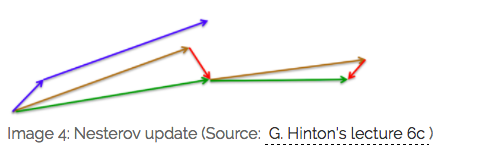
蓝色是 Momentum 的过程,会先计算当前的梯度,然后在更新后的累积梯度后会有一个大的跳跃。
而 NAG 会先在前一步的累积梯度上(brown vector)有一个大的跳跃,然后衡量一下梯度做一下修正(red vector),这种预期的更新可以避免我们走的太快。
NAG 可以使 RNN 在很多任务上有更好的表现。
目前为止,我们可以做到,在更新梯度时顺应 loss function 的梯度来调整速度,并且对 SGD 进行加速。
我们还希望可以根据参数的重要性而对不同的参数进行不同程度的更新。
[应对挑战 2]
- Adagrad
这个算法就可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性,例如识别 Youtube 视频里面的猫,训练 GloVe word embeddings,因为它们都是需要在低频的特征上有更大的更新。
梯度更新规则:
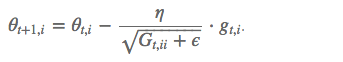
其中 g 为:t 时刻参数 θ_i 的梯度
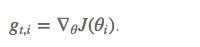
如果是普通的 SGD, 那么 θ_i 在每一时刻的梯度更新公式为:
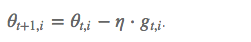
但这里的 learning rate η 也随 t 和 i 而变:
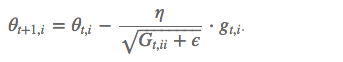
其中 G_t 是个对角矩阵, (i,i) 元素就是 t 时刻参数 θ_i 的梯度平方和。
Adagrad 的优点是减少了学习率的手动调节
超参数设定值:
一般 η 就取 0.01。
缺点:
它的缺点是分母会不断积累,这样学习率就会收缩并最终会变得非常小。
- Adadelta
这个算法是对 Adagrad 的改进,
和 Adagrad 相比,就是分母的 G 换成了过去的梯度平方的衰减平均值,
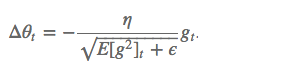
这个分母相当于梯度的均方根 root mean squared (RMS) ,所以可以用 RMS 简写:
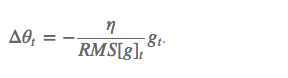
其中 E 的计算公式如下,t 时刻的依赖于前一时刻的平均和当前的梯度:
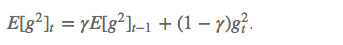
梯度更新规则:
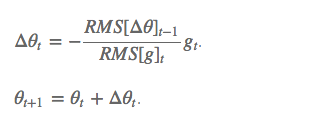
此外,还将学习率 η 换成了 RMS[Δθ],这样的话,我们甚至都不需要提前设定学习率了:
超参数设定值:
γ 一般设定为 0.9,
- RMSprop
RMSprop 是 Geoff Hinton 提出的一种自适应学习率方法。
RMSprop 和 Adadelta 都是为了解决 Adagrad 学习率急剧下降问题的,
梯度更新规则:
RMSprop 与 Adadelta 的第一种形式相同:
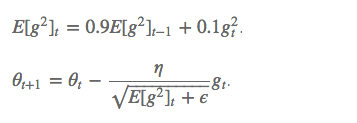
超参数设定值:
Hinton 建议设定 γ 为 0.9, 学习率 η 为 0.001。
- Adam
这个算法是另一种计算每个参数的自适应学习率的方法。
除了像 Adadelta 和 RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的指数衰减平均值:
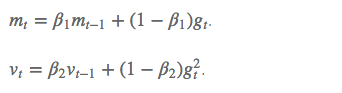
如果 mt 和 vt 被初始化为 0 向量,那它们就会向 0 偏置,所以做了偏差校正,
通过计算偏差校正后的 mt 和 vt 来抵消这些偏差:
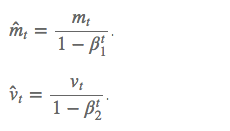
梯度更新规则:
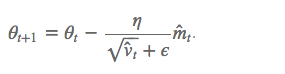
超参数设定值:
建议 β1 = 0.9,β2 = 0.999,? = 10e?8
实践表明,Adam 比其他适应性学习方法效果要好。
- 效果比较?
下面看一下几种算法在鞍点和等高线上的表现:
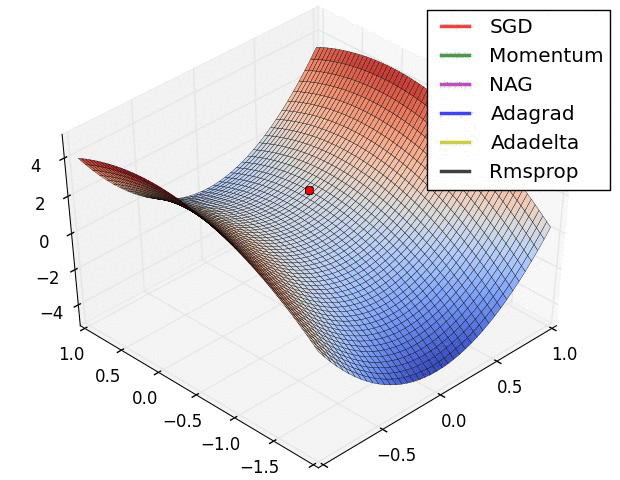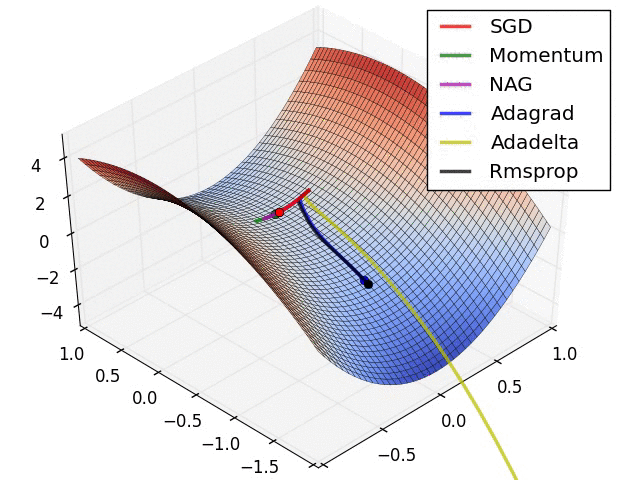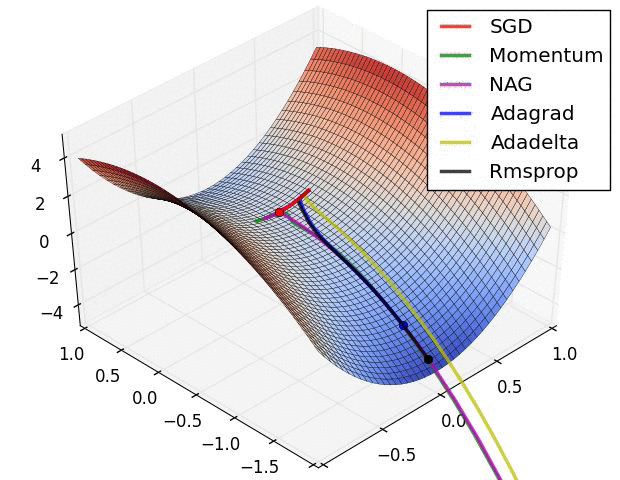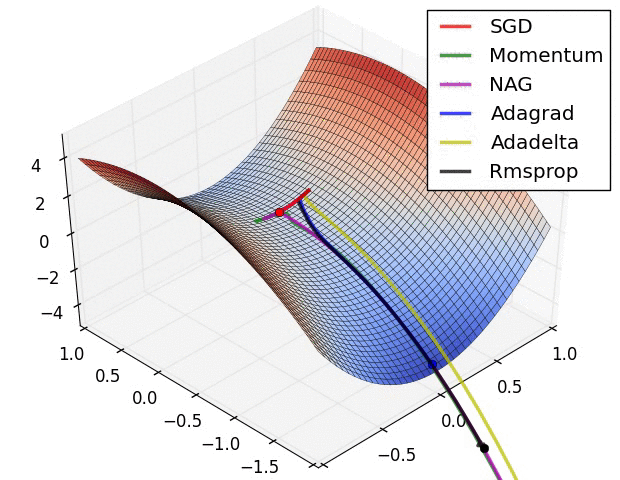
SGD optimization on saddle point
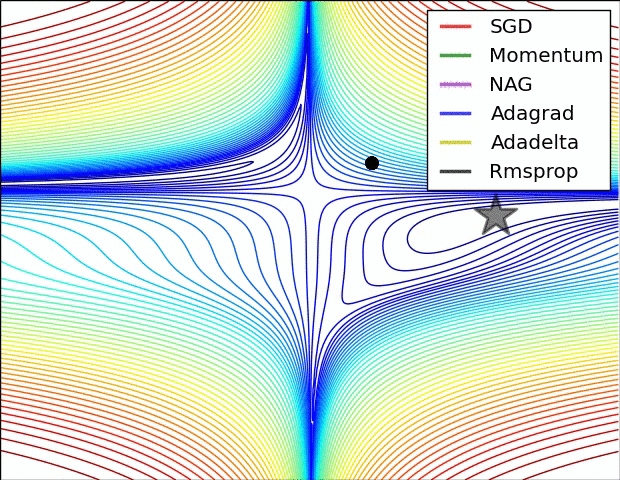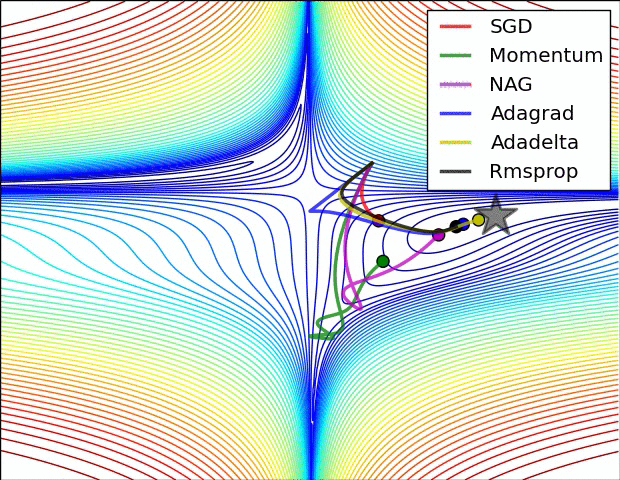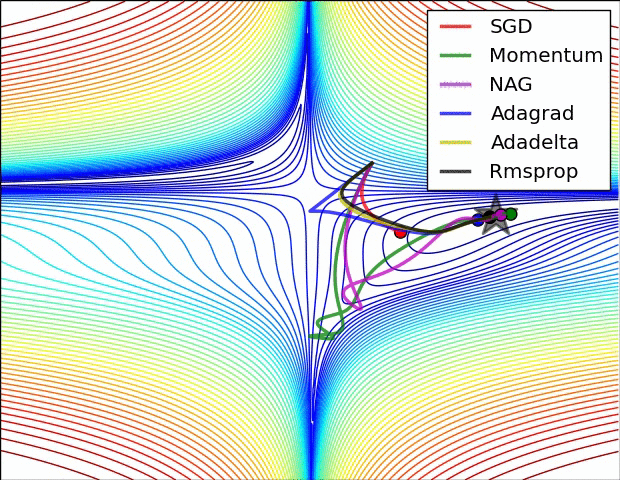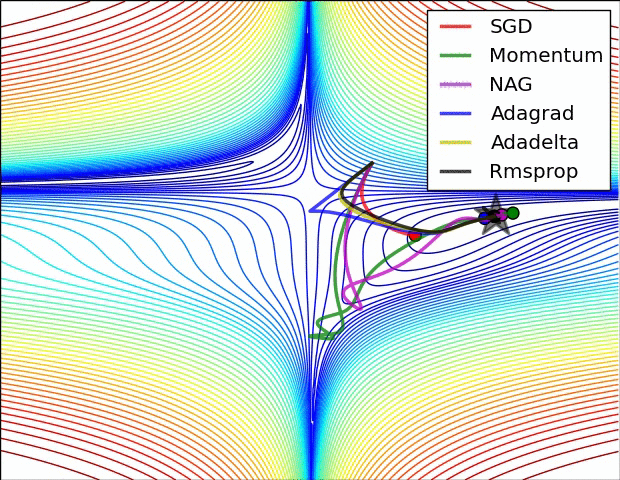
SGD optimization on loss surface contours
上面两种情况都可以看出,Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。
由图可知自适应学习率方法即 Adagrad, Adadelta, RMSprop, Adam 在这种情景下会更合适而且收敛性更好。
- 如何选择?
如果数据是稀疏的,就用自适用方法,即 Adagrad, Adadelta, RMSprop, Adam。
RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum,
随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
很多论文里都会用 SGD,没有 momentum 等。SGD 虽然能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
资料:
http://sebastianruder.com/optimizing-gradient-descent/index.html#fn:24
http://www.redcedartech.com/pdfs/Select_Optimization_Method.pdf
https://stats.stackexchange.com/questions/55247/how-to-choose-the-right-optimization-algorithm




同类文章排行
- 5个印度尼西亚汽车网站
- 关于印发《企业会计准则解释第17号》的通
- 案例展示二
- 案例展示四
- 生产基地三
- 案例展示七
- 【热岗/编制】南宁市疾病预防控制中心/实
- 11大品牌共22款,史上最全无糖希腊酸奶
- 王健林又悄悄卖了几家万达广场!保险、信托
- 视频展示三
最新资讯文章
- 360安全卫士极速版会提示“已锁定默认浏
- 2023年全国两会
- excel排序怎么排名次由小到大公式
- 电竞房什么意思
- How to Write an RFP
- Geavanceerd zoeken
- 2025十大外贸平台品牌排行榜 外贸平台
- 还有人去网吧么?4年消失5万家,爆改也难
- 2022年高考真题 语文 (新高考I卷)
- 五的意思,五的解释,五的拼音,五的部首,
- QS中国内地大学排名一览表(2025最新
- 2025年各省艺术类统考时间汇总
- 5 USD to EUR
- 女演员长相偏美艳更有星光味,娜扎与热巴对
- 个人做外贸怎样起步?这3个步骤教你快速入
- How to Get Help in W
- 生物科技有限公司起名大全,寓意好的生物公
- 高中物理所有位移公式
- 钢琴留学哪个国家比较好
- 2023英国留学硕士学什么专业好?十大热

